



Сайт является визитной карточкой любого бизнеса или проекта в сети Интернет. Однако, иногда возникают ситуации, когда необходимо закрыть сайт или его отдельные части от индексации поисковыми системами. Это может быть вызвано различными причинами: временным закрытием сайта, созданием промо-страницы для определенного события или просто желанием скрыть некоторые разделы сайта от поисковых роботов.
Для решения данной проблемы существуют различные методы. Один из самых популярных способов — использование файла robots.txt. Этот текстовый файл размещается на сервере и содержит инструкции для поисковых систем о том, какие страницы сайта необходимо индексировать, а какие — нет. Чтобы закрыть сайт полностью от индексации, в файле robots.txt можно указать директиву «Disallow: /». Однако, стоит учитывать, что это не гарантирует полной отмены индексации, так как некоторые поисковые системы могут не всегда соблюдать эту инструкцию.
Еще одним эффективным способом является использование метатега «noindex». Добавив этот тег в разметку HTML страницы, вы можете указать поисковым системам, что данная страница не должна быть индексирована. Также, можно применять этот тег к отдельным разделам сайта или к конкретным элементам страниц, что может быть удобно в случае, если требуется закрыть только часть сайта от индексации.
Практические решения для исключения индексации сайта или его части
Иногда владельцы сайтов хотят исключить индексацию определенных страниц или разделов своего сайта. Это может быть связано с различными причинами, как, например, устаревшей или дублирующейся информацией, закрытием временно недоступного раздела или желанием скрыть определенные детали своего бизнеса от поисковых систем. В данном материале мы рассмотрим несколько практических решений, которые помогут вам исключить индексацию сайта или его части.
1. Использование файла robots.txt
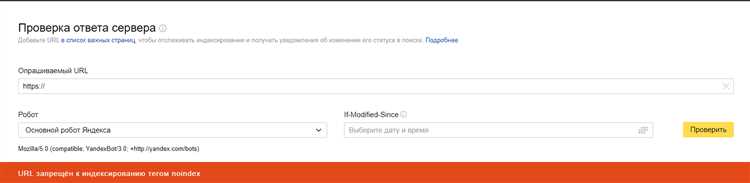

Файл robots.txt является простым текстовым файлом, который указывает поисковым системам, какие страницы или разделы вашего сайта они могут индексировать. Чтобы исключить индексацию определенной страницы или раздела, вам нужно добавить соответствующие директивы в файл robots.txt.
2. Использование мета-тега noindex
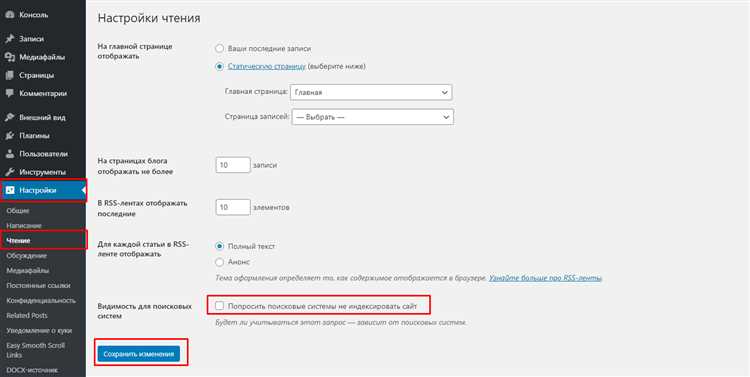

Мета-тег noindex является частью HTML-кода каждой веб-страницы и сообщает поисковым системам, что данная страница или раздел не должны индексироваться. Для исключения индексации определенной страницы или раздела вам необходимо добавить следующий код в соответствующий HTML-файл:
<meta name=»robots» content=»noindex»>
3. Использование мета-тега nofollow
Мета-тег nofollow сообщает поисковым системам, что ссылки на данной странице не должны учитываться при исчислении рейтинга важности для других страниц. Для исключения индексации определенной страницы или раздела, вам нужно добавить следующий код в HTML-файл:
<meta name=»robots» content=»nofollow»>
4. Использование тега rel=»canonical»
Тег rel=»canonical» используется для указания канонической (оригинальной) версии страницы при наличии дублирующегося контента на вашем сайте. Для исключения индексации определенной страницы или раздела, вам нужно добавить следующий код:
<link rel=»canonical» href=»URL страницы/раздела»>
5. Использование файла .htaccess
Файл .htaccess является файлом конфигурации веб-сервера Apache и позволяет вам управлять различными аспектами вашего сайта. Чтобы исключить индексацию определенной страницы или раздела, добавьте следующий код в файл .htaccess:
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} ^.*Googlebot.*$ [NC]
RewriteRule ^страница.html$ — [R=404,L]
Что такое индексация в контексте сайта
Индексация в контексте сайта означает, что поисковая система сканирует все страницы этого сайта и добавляет их в свой поисковый индекс. Это позволяет пользователям находить этот сайт при выполнении соответствующих поисковых запросов. Таким образом, индексация является важным этапом в оптимизации сайта для поисковых систем.
Важность исключения индексации для определенных частей сайта
Существует несколько ситуаций, когда важно исключить индексацию определенных частей сайта от поисковых роботов. Во-первых, это может быть связано с конфиденциальностью информации. Например, на сайте могут быть разделы, доступ к которым предназначен только для определенной аудитории или для зарегистрированных пользователей. В таких случаях необходимо исключить индексацию этих разделов, чтобы информация не попала в поисковые результаты и не стала доступной для всех.
Во-вторых, определенные части сайта могут быть периодически обновляемыми или изменяемыми. Например, это может быть страница с товарами в магазине, которая регулярно обновляется и добавляются новые товары. В таком случае, если поисковые роботы индексируют каждое обновление, это может привести к частому появлению дубликатов контента, что негативно отразится на SEO сайта. Поэтому исключение индексации для таких разделов поможет избежать этой проблемы и сосредоточить поисковиков на главных страницах сайта.
- Таким образом, исключение индексации для определенных частей сайта является важным инструментом для управления поисковой оптимизацией и контроля доступа к конфиденциальной информации.
- Оно позволяет обеспечить безопасность и конфиденциальность данных, а также предотвратить появление дубликатов контента и сосредоточиться на самых важных страницах сайта.
- При этом следует помнить, что исключение индексации может быть осуществлено с помощью метатегов robots или файла robots.txt, и необходимо внимательно рассмотреть каждую ситуацию и выбрать подходящий метод для каждой отдельной части сайта.
Файл robots.txt
Файл robots.txt создается для того, чтобы ограничить доступ поисковых систем к определенным разделам сайта, например, к файлам с конфиденциальной информацией, к частям сайта, не предназначенным для индексации, к временным страницам и т.д. Также в файле robots.txt можно указать путь к файлу sitemap.xml, чтобы уведомить поисковые системы о наличии карты сайта.
Пример содержимого файла robots.txt:
User-agent: * Disallow: /admin/ Disallow: /confidential/ Disallow: /temp/ Sitemap: http://www.example.com/sitemap.xml
В данном примере указано, что для всех поисковых роботов (User-agent: *) запрещен доступ к папкам /admin/, /confidential/ и /temp/. Также указан путь к файлу карты сайта (Sitemap: http://www.example.com/sitemap.xml), который поможет поисковым системам более эффективно индексировать сайт.
Файл robots.txt должен быть создан и размещен в корневой директории сайта. Он должен быть доступен по адресу http://www.example.com/robots.txt, где «www.example.com» — адрес вашего сайта. Из этого файла можно управлять индексацией сайта и уведомлять поисковые системы о необходимых правилах доступа.
Мета-тег robots
Мета-тег robots может быть использован для различных целей. Например, если вы хотите предотвратить индексацию определенных страниц, вы можете добавить значение «noindex» или «nofollow» к тегу. Это полезно в случаях, когда вам не нужно, чтобы поисковые системы индексировали некоторые страницы, например, страницы с личной информацией или формами входа.
В формате HTML данный тег можно добавить внутри секции <head> с помощью тега <meta>. Ниже приведен пример кода с использованием мета-тега robots:
<meta name="robots" content="noindex, nofollow">
В этом примере значение «noindex» указывает, что данная страница не должна быть индексирована, а значение «nofollow» указывает, что на этой странице не должны быть обрабатываны ссылки.
Кроме того, мета-тег robots может содержать и другие значения, такие как «index», «follow», «noarchive» и т. д., которые позволяют управлять индексацией и кэшированием страницы.
Использование мета-тега robots является важной частью SEO-оптимизации, так как позволяет добиться более точной индексации и контроля над тем, как поисковые системы взаимодействуют с вашим сайтом.
Использование HTTP-заголовков
HTTP-заголовки представляют собой специальные метаданные, которые сервер отправляет вместе с HTTP-ответом. Они играют важную роль в контроле и оптимизации процесса индексации сайта поисковыми системами. Использование определенных заголовков позволяет управлять индексацией и отображением контента.
Один из наиболее распространенных заголовков, используемых для закрытия сайта или его частей от индексации, — это «X-Robots-Tag». Этот заголовок позволяет указать поисковым системам, следует ли индексировать страницу или нет. Например, «X-Robots-Tag: noindex» запрещает индексацию страницы, а «X-Robots-Tag: nofollow» запрещает следовать по ссылкам на странице.
Еще один полезный заголовок — «Disallow», который используется в файле robots.txt. Этот заголовок указывает поисковым системам, какие страницы или директории не следует индексировать. Например, «Disallow: /private/» запрещает индексацию всех страниц в директории «private».
HTTP-заголовки предоставляют удобный способ контролировать процесс индексации и отображения контента на вашем сайте. Используя правильные заголовки, вы можете сохранить конфиденциальность частей сайта, предотвратить индексацию дубликатов контента или запретить проследить ссылки на определенных страницах. Важно знать синтаксис и возможности различных заголовков, чтобы правильно настроить их для своего сайта.
Использование noindex


Чтобы закрыть сайт или его отдельные страницы от индексации поисковыми системами, можно использовать мета-тег noindex. Этот тег указывает поисковым роботам не индексировать содержимое страницы, что позволяет предотвратить ее появление в результатах поиска.
Для использования мета-тега noindex необходимо добавить следующий код в секцию HEAD каждой страницы, которую требуется закрыть от индексации:
<meta name="robots" content="noindex">
Такой подход позволяет указать поисковым системам, что страница или весь сайт не должны быть проиндексированы. Это полезно, например, при разработке или тестировании сайта, когда нужно скрыть незавершенные или временные страницы от поисковых систем, чтобы не создавать путаницу для пользователей.
Однако стоит отметить, что использование мета-тега noindex не гарантирует полной блокировки индексации. Некоторые поисковые системы могут игнорировать этот тег или не всегда соблюдать его. Поэтому, если необходима абсолютная блокировка индексации, рекомендуется использовать дополнительные методы, такие как файл robots.txt или мета-теги nofollow для ссылок на закрытые страницы.
Доступ по паролю или IP-адресу
Если вам необходимо закрыть свой сайт или его часть от индексации, вы можете ограничить доступ к нему при помощи пароля или IP-адреса. Таким образом, только пользователи, знающие правильный пароль или имеющие разрешенный IP-адрес, смогут просматривать сайт.
Доступ по паролю
Для создания доступа к сайту по паролю, вам необходимо использовать файл .htaccess, который располагается в корневой директории вашего сайта.
Для начала, создайте файл .htaccess с помощью текстового редактора и добавьте следующий код:
AuthType Basic
AuthName "Закрытая страница"
AuthUserFile /путь_к_файлу/.htpasswd
Require valid-user
Затем, создайте файл .htpasswd, в котором будет храниться пароль пользователя. В этом файле каждый пользователь указывается на новой строке в следующем формате:
имя_пользователя:хэш_пароля
Ваш пароль можно преобразовать в хэш с помощью онлайн-инструментов или команды htpasswd в консоли.
После этого, переместите оба файла .htaccess и .htpasswd в корневую директорию сайта. При попытке доступа к сайту, пользователю будет предложено ввести имя пользователя и пароль для получения доступа.
Доступ по IP-адресу

Для ограничения доступа к сайту по IP-адресу необходимо использовать файл .htaccess также, как и для доступа по паролю.
Добавьте следующий код в файл .htaccess:
Order deny,allow
Deny from all
Allow from ваш_IP_адрес
Замените «ваш_IP_адрес» на реальный IP-адрес, с которого будет разрешен доступ к сайту. Если вы хотите разрешить доступ со всех IP-адресов, используйте следующий код:
Order allow,deny
Allow from all
Сохраните файл .htaccess и поместите его в корневую директорию сайта. Теперь сайт будет доступен только с указанного IP-адреса или со всех IP-адресов в зависимости от вашей настройки.
Итог
Доступ по паролю или IP-адресу позволяет ограничить просмотр сайта только определенным пользователям или с определенных IP-адресов. Это может быть полезно для закрытия сайта от поисковых роботов или ограничения доступа для определенной аудитории. Ключевым моментом является правильная настройка файла .htaccess и .htpasswd для обеспечения безопасности вашего сайта.